
Van data-pijplijnen tot slimme workflows: een blik achter de schermen van AI-gedreven trendrapporten.
Een vraag die te groot is voor ChatGPT
Iedereen die ooit ChatGPT heeft gevraagd: “Verken de hele techwereld en geef me de trends die voor mij relevant zijn” kent het antwoord: een vrij generiek overzicht. Logisch, want ChatGPT is gebouwd voor algemene doeleinden en beperkt zich vaak tot een paar websites en nieuwsbronnen.
Maar wat als er een AI-agent bestond die miljoenen teksten uit techfora en nieuwsfeeds kan analyseren, data filtert op jouw profiel en daaruit patronen destilleert die je direct kunt gebruiken?
|
Building Research Agents for Tech Insights | Towards Data ScienceUsing a controlled workflow, unique data & prompt chaining |
Van eindeloos scrollen naar slimme scouting
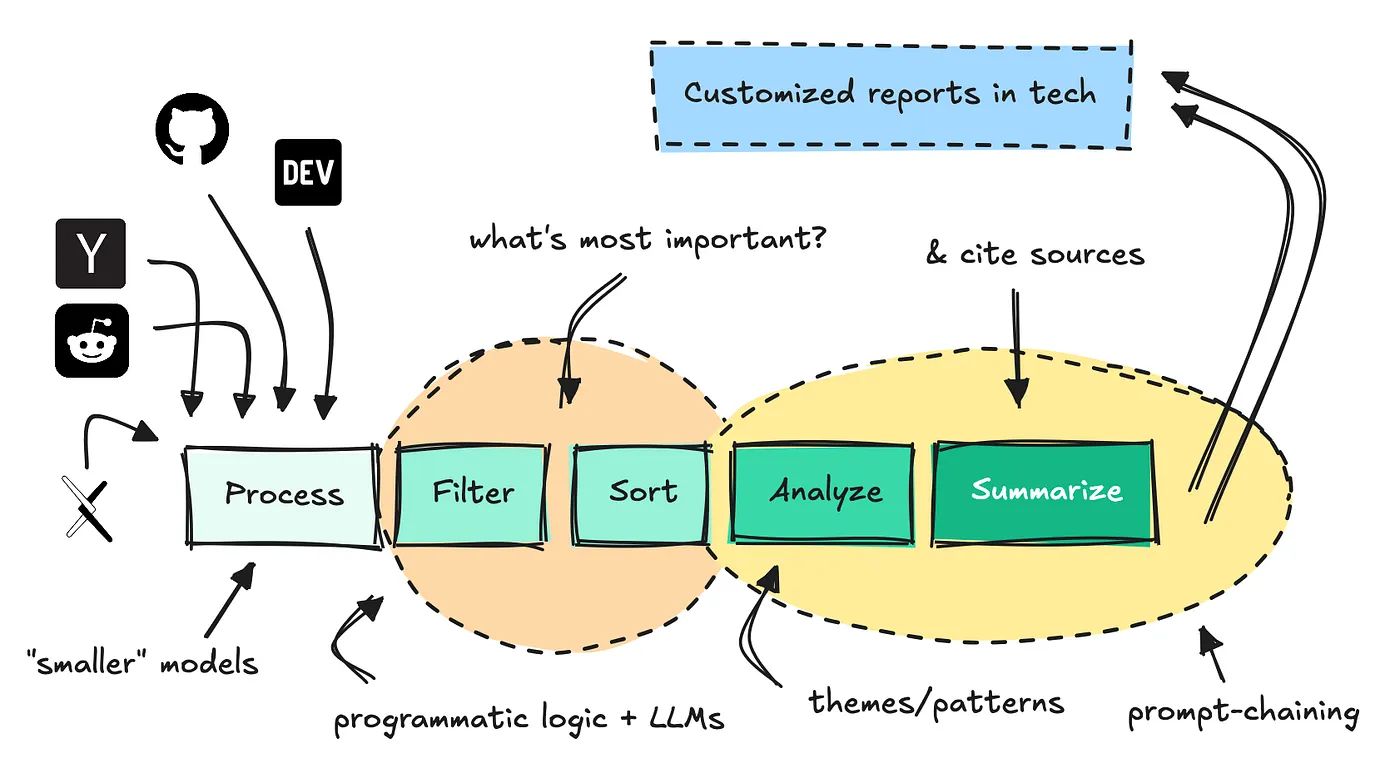
Het doel van zo’n agent is simpel: hij neemt het eindeloze speuren op fora en sociale media van je over. Hij haalt eruit wat ertoe doet, en levert een rapport dat niet alleen actueel is, maar ook afgestemd op jouw persona en interesses.
De sleutel: een gecontroleerde workflow, unieke databronnen en slim prompt chaining.
De bouwstenen van een onderzoeksagent
Om zo’n agent te bouwen, heb je meer nodig dan een AI-model alleen. Drie pijlers zijn essentieel:
- Een schone databron – Dagelijks worden duizenden teksten uit forums en websites ingelezen en geanalyseerd. Kleine NLP-modellen halen trefwoorden, categorieën en sentiment eruit.
- Caching en kostenbeheersing – Door resultaten tijdelijk op te slaan, kost een rapport slechts enkele centen.
- Prompt chaining – Taken worden opgesplitst in kleine stappen: van keywordselectie en fact-extractie tot thematische samenvatting.
Kleine modellen voor grote efficiëntie
Niet elk probleem vraagt om een reus als GPT-5. In dit systeem doen kleine modellen het voorwerk: trefwoorden clusteren, feiten sorteren, irrelevante data filteren. Pas in de laatste fase, waar patronen en samenvattingen belangrijk zijn, komt een groot model in actie.
Zo blijft de workflow betaalbaar, snel én betrouwbaar.
Van profiel naar persoonlijk rapport
De workflow start met het vastleggen van een gebruikersprofiel. Via een slimme prompt vertaalt het systeem jouw voorkeuren in:
- een korte persoonsbeschrijving,
- categorieën,
- maximaal zes trefwoorden,
- de gewenste periode (bv. week of maand),
- voorkeur voor beknopte of uitgebreide samenvattingen.
Met die input bouwt de agent een databron die perfect aansluit bij wat je echt wilt weten.
Trending keywords en feiten-extractie
Wanneer de gebruiker het commando /news geeft, wordt het profiel opgehaald. Het systeem zoekt de meest relevante en trending keywords, haalt de gecachete “feiten” erbij en koppelt die aan de originele bronnen.
Daarna komt de magie van prompt chaining:
- Het eerste model destilleert 5–7 thema’s.
- Het tweede model schrijft samenvattingen in verschillende lengtes, met titel en bronverwijzing.
Resultaat: een helder rapport dat verder gaat dan losse nieuwsartikelen.
Een kijkje in de praktijk
De auteur bouwde de agent als Discord-bot, maar de architectuur is overal toepasbaar. Het hele proces duurt enkele minuten, afhankelijk van caching. Voor wie zelf wil experimenteren, is er een repository beschikbaar én een open Discord-kanaal.
Waarom dit ertoe doet
AI-agents zijn geen magie: ze vereisen degelijk software- en data-engineering. Zonder goede pijplijnen en gestructureerde output blijft een LLM zweven. Het echte werk zit in het vertalen van natuurlijke taal naar bruikbare, gevalideerde JSON-structuren.
De volgende stap: Inspiratie voor makers
Elke agent is anders, en er bestaat geen blauwdruk. Maar wie zelf wil bouwen, kan dit voorbeeld zien als inspiratiebron. Of je nu een tech-scouting bot maakt, een contentgenerator of iets geheel nieuws – de boodschap is duidelijk: AI werkt pas echt goed als er een sterke workflow achter zit.









