Stel je voor: iemand leest een wetenschappelijk artikel, zijn ogen glijden over de zinnen, soms schieten ze terug naar een eerder woord, en ondertussen lichten de hersenen op in patronen die alleen met een fMRI-scanner zichtbaar worden. Dit was het toneel van een nieuw onderzoek waarin wetenschappers wilden weten: hoe dicht komen grote taalmodellen eigenlijk bij dit menselijke proces?
Het experiment: Mensen en machines naast elkaar
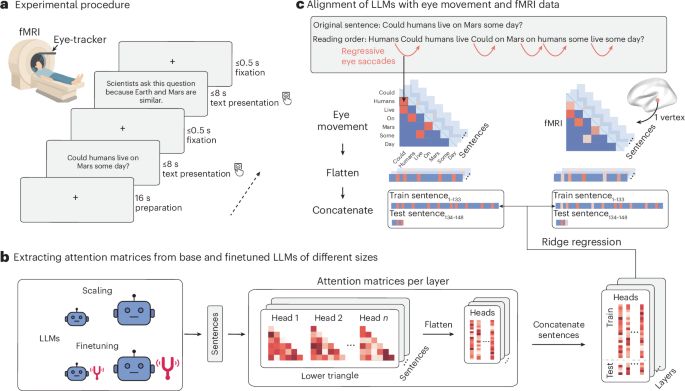
Onderzoekers lieten proefpersonen vijf Engelstalige STEM-artikelen lezen terwijl hun oogbewegingen en hersenactiviteit nauwgezet werden gevolgd. Tegelijkertijd kregen grote taalmodellen dezelfde teksten voorgeschoteld. Het doel: zien of de manier waarop modellen “aandacht verdelen” over woorden lijkt op hoe mensen lezen en verwerken.
|
Increasing alignment of large language models with language processing in the human brain - Nature Computational ScienceTransformer-based large language models (LLMs) have considerably advanced our understanding of how meaning is represented in the human brain; however, the validity of increasingly large LLMs is being questioned due to their extensive training data and their ability to access context thousands of words long. |
Grootte blijkt doorslaggevend
Het resultaat was opvallend duidelijk. Hoe groter het model, hoe sterker de overeenkomst met menselijk gedrag en hersenactiviteit. Modellen met miljarden parameters wisten de leespatronen veel beter te spiegelen dan hun kleinere broertjes.Met andere woorden: schaal doet ertoe.
Instructietuning verrast niet
Veel onderzoekers hadden gedacht dat instructietuning – het extra trainen van modellen om opdrachten te volgen – de kloof met menselijke verwerking zou verkleinen. Maar in dit experiment bleek dat nauwelijks verschil te maken. Voor het begrijpen van natuurlijke tekst lijkt vooral de omvang van het model de sleutel.
Van oogbeweging tot hersensignaal
De vergelijking ging diep: onderzoekers keken niet alleen naar hersenactiviteit in de scanner, maar ook naar oogbewegingen, zoals terugkerende saccades (wanneer een lezer terugbladert in een zin). De patronen van grotere modellen bleken opvallend goed te passen bij deze menselijke neigingen.
Over grenzen en talen heen
Interessant genoeg bleven de resultaten overeind in andere contexten. Niet alleen bij Engelse leesteksten, maar ook bij Chinese luisterfragmenten werd duidelijk: grotere modellen zijn consistenter in lijn met hoe mensen taal verwerken. Dit suggereert dat het fenomeen universeel kan zijn.
Waarom dit ertoe doet
De bevindingen zijn meer dan een wetenschappelijk weetje. Als taalmodellen steeds beter overeenkomen met hoe mensen taal begrijpen, kunnen ze waardevolle hulpmiddelen worden voor hersenonderzoek, taalpsychologie en misschien zelfs bewustzijnsstudies. Het opent de deur naar een toekomst waarin kunstmatige en menselijke taalverwerking steeds meer met elkaar vervlochten raken.
Maar schaal heeft zijn prijs
Toch klinkt er ook een waarschuwing. Grotere modellen vragen gigantische hoeveelheden rekenkracht, geheugen en energie. Daarmee wordt het speelveld kleiner: alleen grote techbedrijven kunnen zulke modellen ontwikkelen. De vraag blijft of dit pad wel duurzaam is.
De weg vooruit
Voor nu is de boodschap duidelijk: wie de menselijke hersenen beter wil nabootsen, moet vooral groter bouwen. Maar onderzoekers wijzen erop dat dit slechts één kant van het verhaal is. Misschien ligt de echte toekomst in nieuwe vormen van training die niet alleen meer data, maar ook meer menselijke nuance toevoegen.









