
Documenten. Ze blijven een hoofdbreker in veel organisaties. Facturen, formulieren, contracten – ze stromen binnen in allerlei formaten, vaak ongestructureerd, soms onleesbaar, en zelden gestandaardiseerd. Handmatige verwerking is foutgevoelig en duur, en traditionele automatiseringstechnieken schieten tekort.
Maar daar wil Amazon met zijn nieuwste technologie verandering in brengen. In een wereld waar data goud waard is, lanceert het bedrijf een oplossing die niet alleen leest, maar ook begrijpt en leert: Amazon Bedrock Data Automation.
De belofte: Documenten die zichzelf verwerken
Stel je voor: een systeem dat automatisch weet welk type document het voor zich heeft. Dat zelfstandig de juiste gegevens eruit haalt, ze herkent, controleert en omzet naar consistente, bruikbare informatie – volledig schaalbaar en zonder menselijke tussenkomst, tenzij nodig. Dat is precies wat Amazon met Bedrock Data Automation heeft gebouwd.
Deze aanpak is gebaseerd op zogeheten “blueprints” – kant-en-klare logica die documenten intelligent analyseert. In plaats van te vertrouwen op starre regels, gebruikt het systeem AI om flexibel om te gaan met verschillende layouts, teksten en datatypes.
Niet zomaar OCR, maar echte intelligentie
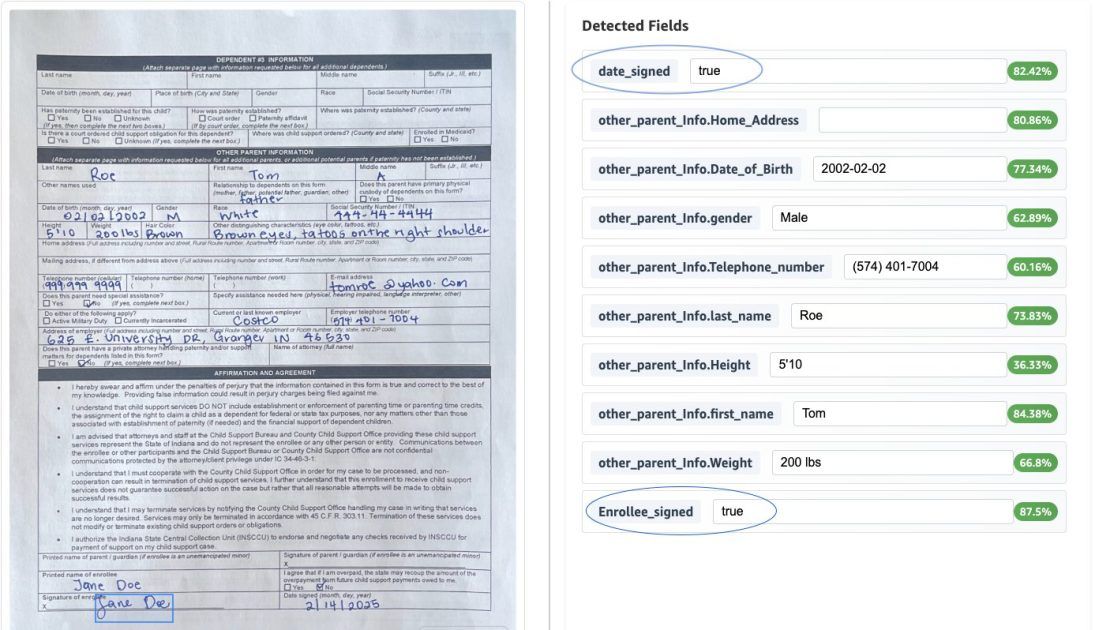
In tegenstelling tot klassieke OCR-oplossingen die simpelweg tekst digitaliseren, gaat Bedrock veel verder. Het koppelt vertrouwen aan elk data-element met zogeheten ‘confidence scores’, gebruikt bounding boxes om aan te geven waar gegevens exact zijn gevonden, en voert automatische normalisatie uit. Een datum als “16/08/25” wordt uniform omgezet naar “2025-08-16”, ongeacht het oorspronkelijke formaat.
Daarnaast herkent het systeem complexe entiteiten. Adresvelden worden netjes opgesplitst in straatnaam, huisnummer, postcode en land. En dankzij validatieregels controleert de AI zelf of een btw-nummer wel geldig is of een bedrag binnen de verwachte marges valt.
En als het fout dreigt te gaan? Dan helpt een mens
Bij twijfel of lage betrouwbaarheid schakelt het systeem automatisch een menselijke reviewer in via Amazon Augmented AI (A2I). Die menselijke correcties worden vervolgens gebruikt om het model bij te sturen – een continue leerlus.
Zo combineert Amazon het beste van twee werelden: de snelheid van machines met de nuance van mensen.
Een serverless architectuur onder de motorkap
Het hele proces draait in de cloud, zonder dat bedrijven servers hoeven te beheren. De documenten worden via Amazon S3 opgeslagen en in segmenten opgedeeld. Elk segment doorloopt vervolgens een serie stappen via AWS Step Functions, waarbij extractie, normalisatie, validatie en transformatie automatisch plaatsvinden.
Uiteindelijk vloeien de verwerkte gegevens naar je favoriete systemen: van datalakes tot CRM-oplossingen. Alles is schaalbaar, aanpasbaar en ontworpen voor grote hoeveelheden documenten.
Wat betekent dit concreet voor bedrijven?
Organisaties die kampen met bergen aan ongestructureerde documenten – denk aan financiële instellingen, zorgverleners of logistieke bedrijven – kunnen hiermee enorme efficiëntieslagen maken. Niet alleen worden fouten gereduceerd, maar ook de verwerkingstijd daalt drastisch.
Bovendien hoeven ontwikkelaars het wiel niet opnieuw uit te vinden. De meegeleverde blueprints maken snelle implementatie mogelijk, zelfs voor teams zonder diepgaande AI-kennis.
De toekomst van documentverwerking is zelfdenkend
Wat vroeger een traag, moeizaam proces was, wordt dankzij Amazon Bedrock Data Automation een gestroomlijnde datastroom. Met AI die niet alleen teksten leest, maar ook context begrijpt, fouten voorkomt en meegroeit met je organisatie.
Een stille revolutie, in de vorm van slimme documentverwerking.
|
Scalable intelligent document processing using Amazon Bedrock Data Automation | Amazon Web ServicesIn the blog post Scalable intelligent document processing using Amazon Bedrock, we demonstrated how to build a scalable IDP pipeline using Anthropic foundation models on Amazon Bedrock. Although that approach delivered robust performance, the introduction of Amazon Bedrock Data Automation brings a new level of efficiency and flexibility to IDP solutions. This post explores how Amazon Bedrock Data Automation enhances document processing capabilities and streamlines the automation journey. |









