
In de wereld van kunstmatige intelligentie draait alles om snelheid en schaal. Bedrijven willen hun modellen zo snel mogelijk trainen, liefst tegen lagere kosten. AWS speelt daarop in met een opvallende innovatie: SageMaker HyperPod krijgt een upgrade die rekening houdt met de fysieke en logische structuur van het datacenter zelf.
Wat betekent dat concreet? AI-taken worden voortaan niet meer zomaar willekeurig verdeeld over servers, maar slim gescheduled op basis van hun “netwerk-nabijheid”.
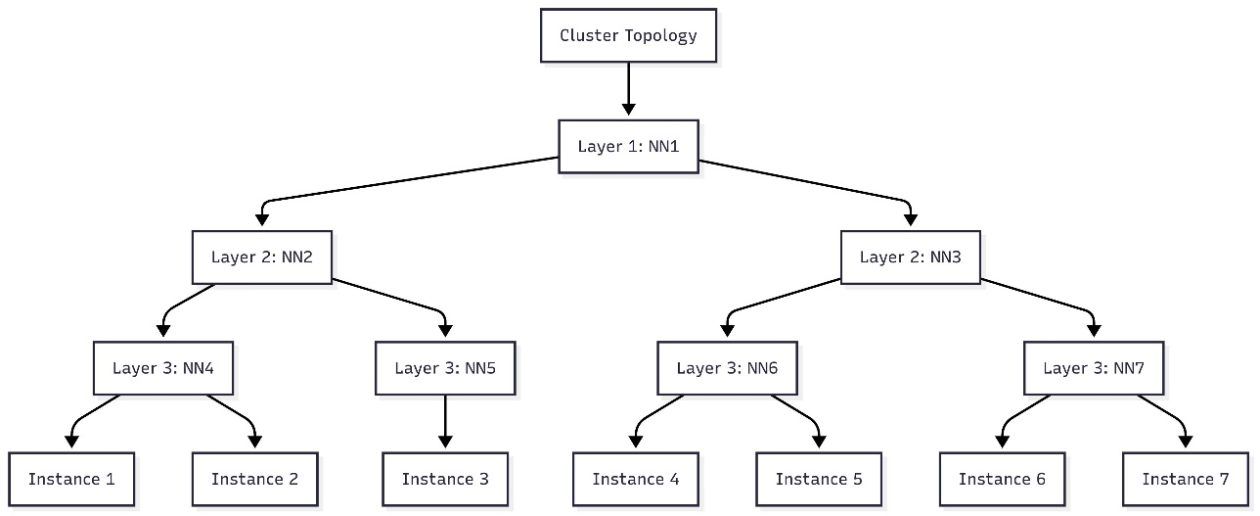
Waarom netwerk-topologie zo belangrijk is
Wie ooit een teamproject deed, weet dat communicatie cruciaal is. Zet collega’s die constant moeten overleggen in hetzelfde kantoor, en de efficiëntie schiet omhoog. Datzelfde principe geldt nu voor AI-training.
|
Schedule topology-aware workloads using Amazon SageMaker HyperPod task governance | Amazon Web ServicesIn this post, we introduce topology-aware scheduling with SageMaker HyperPod task governance by submitting jobs that represent hierarchical network information. We provide details about how to use SageMaker HyperPod task governance to optimize your job efficiency. |
Wanneer GPU’s en rekenknooppunten in een datacenter veel data moeten uitwisselen, kan de afstand in het netwerk het verschil maken. Met de nieuwe topology-aware scheduling kiest SageMaker ervoor om die taken dichter bij elkaar te plaatsen, zodat ze sneller met elkaar kunnen “praten”. Het resultaat: minder vertraging, minder verspilde bandbreedte en een flinke boost in prestaties.
Van theorie naar praktijk
AWS maakt het voor data scientists en engineers relatief eenvoudig. Met een paar aanpassingen in hun workflow kunnen ze aangeven of taken moeten of bij voorkeur op bepaalde knooppunten draaien.
- Met Kubernetes manifests: door annotaties toe te voegen kan men de gewenste topologie specificeren.
- Met de HyperPod CLI: via eenvoudige parameters zoals --preferred-topology kan men voorkeuren instellen.
Daarbovenop zorgt de governance-laag van HyperPod dat middelen eerlijk verdeeld worden. Zo krijgt geen enkel project een oneerlijke voorsprong, en blijven clusters stabiel draaien.
Wat levert het op?
Voor organisaties die grote taalmodellen of generatieve AI trainen, kan elke seconde telt. AWS claimt dat deze nieuwe aanpak latency aanzienlijk verlaagt en het gebruik van dure GPU’s optimaliseert. Dat betekent niet alleen kortere trainingstijden, maar ook lagere kosten—een belangrijk argument voor bedrijven die AI-investeringen rendabel willen maken.
De weg vooruit
Met deze stap zet AWS SageMaker HyperPod steviger in de markt als hét platform voor grootschalige AI-training. De kans is groot dat dit nog maar het begin is. Verwacht wordt dat er in de toekomst meer automatisering en fijnmazige controle over netwerkstructuren zal volgen.
Wat nu al duidelijk is: wie inzet op topology-aware training, krijgt een voorsprong in de AI-race.









