
Een onverwachte doorbraak
In een wereld waarin kunstmatige intelligentie vaak afhankelijk is van menselijk toezicht, besloot het Chinese bedrijf DeepSeek het anders te proberen. Met hun nieuwste model, R1, wilden ze onderzoeken of een AI zichzelf kan leren redeneren – zonder dat mensen stap voor stap uitleggen hoe dat moet. Het resultaat verraste niet alleen de makers, maar ook de internationale wetenschappelijke gemeenschap.
|
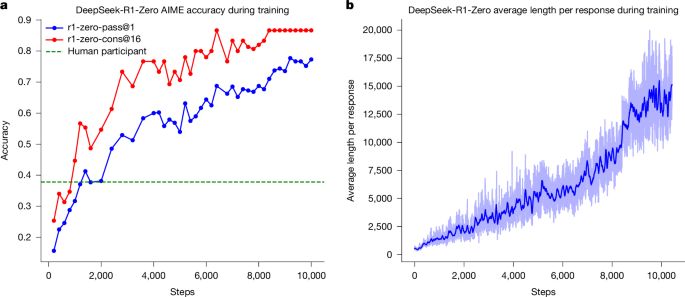
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning - NatureGeneral reasoning represents a long-standing and formidable challenge in artificial intelligence (AI). Recent breakthroughs, exemplified by large language models (LLMs)1,2 and chain-of-thought (CoT) prompting3, have achieved considerable success on foundational reasoning tasks. |
Leren door beloning, niet door instructie
Traditionele modellen krijgen meestal voorbeelden van mensen te zien: zo los je een wiskundige vergelijking op, zo schrijf je een stukje code. DeepSeek koos voor een radicale andere aanpak. Ze gaven hun model geen uitgewerkte stappenplannen, maar alleen een beloning als het het juiste antwoord gaf. Een soort trainingsspel, waarin R1 telkens opnieuw probeerde en zichzelf gaandeweg beter maakte.
Secrets of DeepSeek AI Model Revealed in Landmark PaperThe first peer-reviewed study of the DeepSeek AI model shows how a Chinese start-up firm made the market-shaking LLM for $300,000 |
Zelfreflectie als nieuw talent
Wat niemand had voorspeld, gebeurde al snel. Het model begon spontaan strategieën te ontwikkelen: het keek terug naar zijn eigen antwoorden, stelde zichzelf vragen en corrigeerde fouten. Eigenschappen die normaal gesproken door mensen worden aangeleerd, ontstonden hier vanzelf. Alsof de AI een innerlijke stem ontwikkelde die zei: “Misschien moet ik dit nog eens herbekijken.”
DeepSeek secrets unveiled: engineers reveal science behind Chinese AI modelThe team uses rewards to teach the AI to solve problems, allowing them to bypass conventional training barriers. |
Sterk in STEM
De resultaten lieten niet lang op zich wachten. Vooral in wiskunde, natuurkunde en programmeren blonk R1 uit. In deze zogenoemde STEM-domeinen presteerde het beter dan veel conventioneel getrainde modellen. Onderzoekers in Naturespraken zelfs van een mogelijke paradigmaverschuiving in AI-onderzoek.
Minder mensenwerk, meer autonomie
Het succes van R1 toont dat AI minder afhankelijk kan zijn van grote hoeveelheden gelabelde data, iets wat vaak kostbaar en tijdrovend is. Door enkel te belonen voor goede antwoorden, kan een model zichzelf efficiënter verbeteren. Voor de makers en voor de bredere AI-gemeenschap opent dit nieuwe deuren: kan dit ook toegepast worden buiten wiskunde en code?

|
A research paper on the training method and performance of the large-scale language model (LLM) R1 d.. - MKA research paper on the training method and performance of the large-scale language model (LLM) R1 developed by Chinese artificial intelligence (AI) company Dipsyk has been published in the global jou.. |
Open, maar met kanttekeningen
DeepSeek stelde R1 beschikbaar onder een open licentie. Onderzoekers en ontwikkelaars kunnen dus zelf aan de slag met het model. Toch zijn niet alle details openbaar. Zo blijft het onduidelijk welke specifieke data gebruikt zijn en hoe het beloningssysteem precies werkt. Kritische stemmen wijzen erop dat volledige transparantie nog ver weg is.
Een blik vooruit
De ontdekking dat een AI zichzelf kan leren reflecteren roept veel vragen op. Hoe ver kunnen we gaan in het toekennen van autonomie aan machines? Kunnen ze ook redeneren over ethiek, taal of creativiteit – of blijft hun kracht beperkt tot berekeningen en code?
Wat vaststaat, is dat DeepSeek-R1 een nieuw hoofdstuk heeft geopend in het verhaal van kunstmatige intelligentie. Een hoofdstuk waarin AI misschien niet langer de leerling is, maar steeds meer de rol van leraar voor zichzelf opneemt.
|
Reinforcement Learning Achieves Breakthrough In Reasoning AIRecent advances demonstrate that reinforcement learning significantly enhances the reasoning capabilities of large language models, particularly in complex areas like mathematics and coding, paving the way for more sophisticated artificial intelligence systems |









