
In de snelle evolutie van kunstmatige intelligentie (AI) wordt steeds duidelijker dat krachtige modellen alleen niet genoeg zijn. Context, oftewel de achtergrondinformatie en omstandigheden rondom een taak, blijkt de sleutel te zijn voor betere prestaties, betrouwbaarheid en relevantie. In dit artikel onderzoekt de auteur waarom “context engineering” het volgende grote thema is in AI — en hoe RAG (Retrieval-Augmented Generation) daarin een spilfunctie vervult.
Wat is RAG en waarom is het belangrijk?
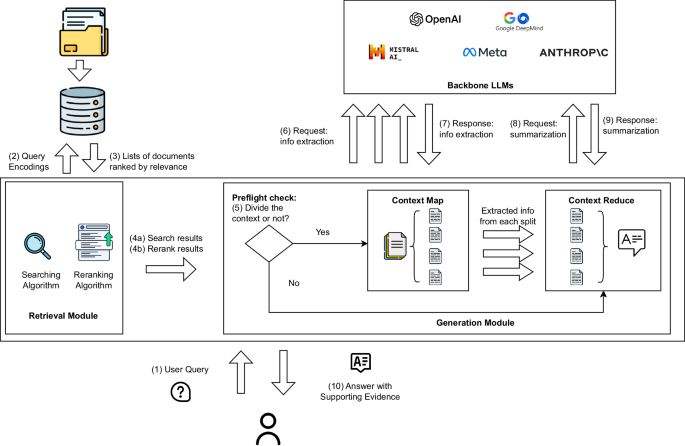
RAG, oftewel Retrieval-Augmented Generation, is een aanpak waarbij een AI-model niet alleen vertrouwt op wat het eerder geleerd heeft, maar ook relevante externe informatie ophaalt (uit documenten, databases, internet) om een taak uit te voeren.
Retrieval-augmented generation - WikipediaRetrieval-augmented generation (RAG) is a technique that enables large language models (LLMs) to retrieve and incorporate new information.[1] With RAG, LLMs do not respond to user queries until they refer to a specified set of documents. |
Deze methode helpt om drie belangrijke problemen te bestrijden:
- Verouderde kennis — modellen kunnen informatie uit recente bronnen meenemen.
- “Hallucinaties” — onterechte beweringen doordat modellen gissen zonder concrete bronnen.
- Beperkte domeinspecifieke kennis — RAG maakt toepassingen mogelijk in gespecialiseerde vakgebieden.
Why context is the new currency of AI: The power of knowledge graphsExplore how knowledge graphs are transforming AI, highlighting their role in bridging the 'context crisis' and paving the way for effective real-world applications. |
Van prompt engineering naar context engineering
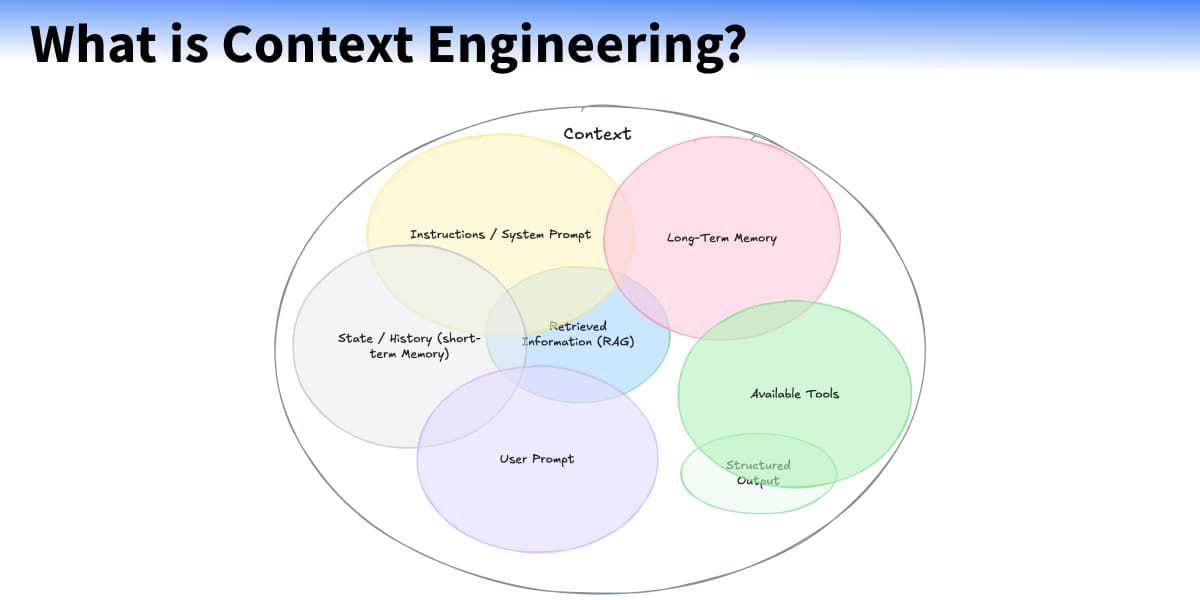
Hoewel “prompt engineering” (het zorgvuldig formuleren van opdrachten aan het AI-model) nog steeds belangrijk is, verschuift de aandacht naar een veel breder begrip: context engineering. Dat betekent: zorgen dat het model niet alleen de onmiddellijke opdracht (prompt) krijgt, maar ook alle relevante achtergrondinformatie, hulpmiddelen en geschiedenis die nodig zijn om die opdracht goed uit te voeren.
|
The New Skill in AI is Not Prompting, It's Context EngineeringContext Engineering is the new skill in AI. It is about providing the right information and tools, in the right format, at the right time. |
De elementen van context kunnen zijn:
- vorige gesprekken of instructies (geschiedenis),
- tools of methodes die het model mag gebruiken,
- externe kennis (via RAG),
- het doel of de bedoeling van de gebruiker,
- de juiste presentatievorm van informatie.
Uitdagingen voor context engineering
- Groei en relevantie van de contextHoe meer informatie, hoe beter — maar te veel kan ook verwarrend worden. De kunst is relevante context te selecteren zonder te “verzuipen” in irrelevante details.
- Positie en prioriteitNiet alle context wordt gelijk geïnterneerd: wat “eerder” of “later” geleverd wordt, kan invloed hebben op de uitkomst.
- Onderhoud en actualiteitContext moet up-to-date zijn en aangepast worden wanneer omstandigheden veranderen.
- Complexiteit van systeemopbouwHet vergt infrastructuur en ontwerp om context dynamisch te leveren, te filteren en in te passen. Niet elke toepassing of organisatie is daar klaar voor.
Attributing Response to Context: A Jensen-Shannon Divergence Driven Mechanistic Study of Context Attribution in Retrieval-Augmented GenerationAbstract page for arXiv paper 2505.16415: Attributing Response to Context: A Jensen-Shannon Divergence Driven Mechanistic Study of Context Attribution in Retrieval-Augmented Generation |
Impact en voorbeelden
- Betere prestaties in specialistische domeinen zoals geneeskunde of juridische teksten, waar nauwkeurige broninformatie en actuele data cruciaal zijn.
- Efficiëntere ontwikkelingsprocessen, omdat modellen niet steeds opnieuw getraind hoeven te worden — de externe bronnen kunnen up-to-date blijven terwijl het model zelf stabiel blijft.
- Toegenomen betrouwbaarheid en transparantie, doordat AI-uitvoer gesteund wordt door externe verificeerbare bronnen.
|
Leveraging long context in retrieval augmented language models for medical question answering - npj Digital MedicineWhile holding great promise for improving and facilitating healthcare through applications of medical literature summarization, large language models (LLMs) struggle to produce up-to-date responses on evolving topics due to outdated knowledge or hallucination. Retrieval-augmented generation (RAG) is a pivotal innovation that improves the accuracy and relevance of LLM responses by integrating LLMs with a search engine and external sources of knowledge. However, the quality of RAG responses can be largely impacted by the rank and density of key information in the retrieval results, such as the “lost-in-the-middle” problem. In this work, we aim to improve the robustness and reliability of the RAG workflow in the medical domain. Specifically, w |
De AI-wereld staat op een kantelpunt: modellen, hoe groot en krachtig ook, presteren nauwelijks goed zonder de juiste context. RAG heeft bewezen een waardevolle brug te zijn tussen statische training en dynamische informatievoorziening. Maar de volgende stap, context engineering, richt zich op het systematisch ontwerpen van die brug: welke context is nodig, wanneer, in welke vorm, en hoe wordt die onderhouden?
Organisaties en ontwikkelaars die daarin investeren, hebben de beste kans om AI-systemen te bouwen die niet alleen slim zijn, maar ook verstandig, relevant en betrouwbaar.









