
Google werkt aan een ingrijpende verandering in hoe we zoeken met onze stem. Het bestaande systeem — eerst audio naar tekst, daarna zoeken — blijkt gevoelig voor fouten in de transcriptie. In plaats daarvan introduceert Google Speech-to-Retrieval (S2R): een nieuwe AI-gebaseerde aanpak die rechtstreeks van gesproken vraag naar relevante resultaten gaat, zonder de tussenstap van tekst. Dit zou voice search fundamenteel kunnen verbeteren.
|
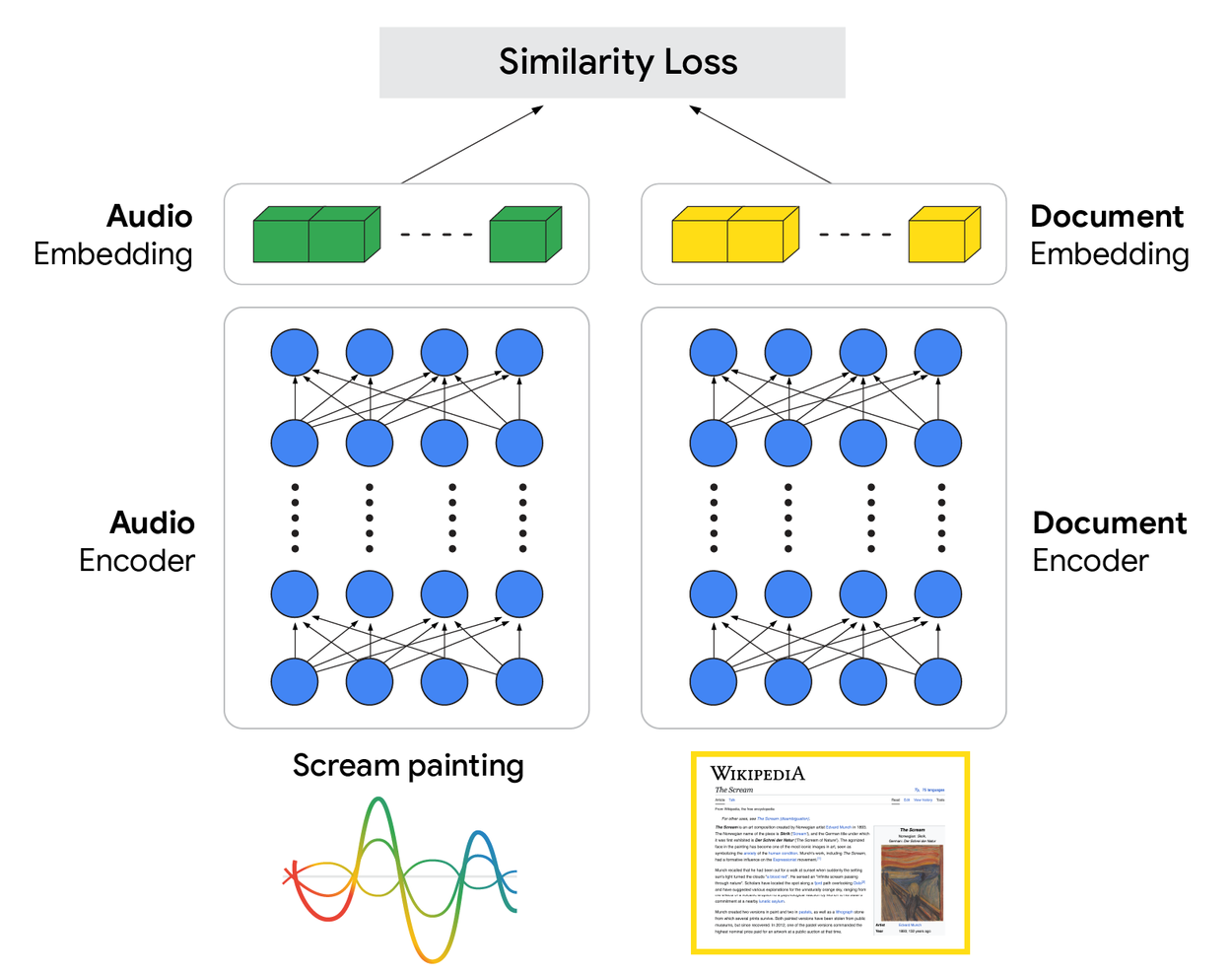
Speech-to-Retrieval (S2R): A new approach to voice searchThe key to this model is how it is trained. Using a large dataset of paired audio queries and relevant documents, the system learns to adjust the parameters of both encoders simultaneously. |
De uitdagingen van de klassieke cascade-methode
Tot nu toe verliep stemzoektechnologie via een zogenoemd “cascade modeling”-model: eerst zet een automatisch spraakherkenningssysteem (ASR) gesproken audio om in tekst, daarna gebruikt een traditionele zoekmachine die tekst om relevante documenten te vinden. Maar dat proces kent een zwakte: als de transcriptie een fout bevat (bijvoorbeeld een uitgesproken woord verkeerd verstaan), dan kan de betekenis veranderen en leiden tot irrelevante zoekresultaten. Het klassieke voorbeeld: iemand zoekt “The Scream” (het beroemde schilderij), maar een kleine interpretatiefout in de transcriptie verandert het in “screen”, waardoor zoekresultaten over schermen verschijnen.
Door deze foutgevoeligheid stapelt de impact zich op: fouten in het transcriptieproces worden doorgegeven aan de zoekmachine, die niet altijd kan corrigeren wat verkeerd begrepen is.
Wat is Speech-to-Retrieval (S2R)?
S2R is een radicaal ander AI-model dat probeert de tussenstap van transcriptie te omzeilen. In plaats van te vragen “welke woorden zijn er gezegd?”, richt het zich op “welke informatie wordt gezocht?”
De kern van S2R is een dual-encoder architectuur:
- Een audio encoder verwerkt de binnenkomende spraak en genereert een vector (embedding) die de semantische betekenis van de vraag vastlegt.
- Parallel daaraan leert een document encoder documenten in vectorvorm te representeren.Tijdens training leert het systeem zodanig dat de audio-embedding dicht in vectorruimte ligt bij de embedding van geschikte documenten. Zo koppelt het direct audio aan relevante content, zonder eerst een woord-voor-woord transcriptie.
Wanneer een gebruiker een gesproken vraag stelt, wordt het via de audio encoder vertaald in een vector, waarna deze vector wordt gebruikt om in de index de best passende documenten op te halen. Daarna beslist het rangschikcijferingssysteem welke documenten het meest relevant zijn.
Prestaties: Kan S2R de klassieke aanpak overtreffen?
De onderzoekers vergeleken drie modellen:
- Cascade ASR — de huidige standaardaanpak.
- Cascade groundtruth — de “perfecte transcriptie” variant, als benchmark.
- S2R-model — de nieuwe benadering.
In hun evaluatie op de “Simple Voice Questions” (SVQ) dataset (vragen in 17 talen en 26 regio’s) bleek dat S2R het klassieke cascade-model significant overtrof, en zelfs redelijk dicht in de buurt kwam van de prestaties van de ideale cascade-methode. Toch is er nog een kloof: S2R bereikt niet volledig de prestaties van de perfecte cascade-variant, wat aangeeft dat verder onderzoek nodig blijft.
Live in gebruik: De eerste concrete stap
S2R is geen theoretisch experiment — Google heeft het al geïmplementeerd in bepaalde producten in meerdere talen, waarmee gebruikers een merkbare verbetering in stemzoekervaring krijgen.
Daarnaast zet Google in op open wetenschap: de SVQ-dataset is vrijgegeven als onderdeel van het Massive Sound Embedding Benchmark (MSEB) en nodigt onderzoeksgemeenschappen uit om verder te bouwen op deze technologie.
Waarom AI de spil is van deze revolutie
De introductie van S2R is een helder voorbeeld van hoe AI opnieuw de onderliggende architectuur van systemen transformeert:
- In plaats van louter woordherkenning, leert het systeem betekenisvolle relaties tussen gesproken taal en content.
- Fouten in transcriptie — een zwakte van klassieke systemen — worden grotendeels geëlimineerd, omdat het model niet afhankelijk is van een perfecte transcriptie.
- De dual-encoder structuur en training op semantische vectorrepresentaties illustreren de kracht van diepe leertechnieken (deep learning) en AI in moderne spraaksystemen.
Kortom: S2R illustreert hoe AI niet alleen “slimmer luisteren” mogelijk maakt, maar rechtstreeks toegang tot informatie faciliteert.
In de overgang van spraak naar informatie zet Google met S2R een belangrijke stap: een aanpak die de klassieke afhankelijkheid van spraak-naar-tekst doorbreekt. Het resultaat? Snellere, betrouwbaardere voice search. AI is de stille kracht achter deze revolutie. Terwijl het model al in gebruik is en datasets openbaar zijn, blijft verdere verfijning nodig. Maar de richting is duidelijk: de toekomst van spraakinteractie plaatst betekenis vóór woorden — dankzij AI.









