
Hoe Google’s nieuwste agent-achtige visuele AI-tool visuele redeneerprocessen combineert met code-uitvoering om beeldinzicht te verdiepen en de nauwkeurigheid van antwoorden te vergroten.
Van statisch kijken naar actief begrijpen
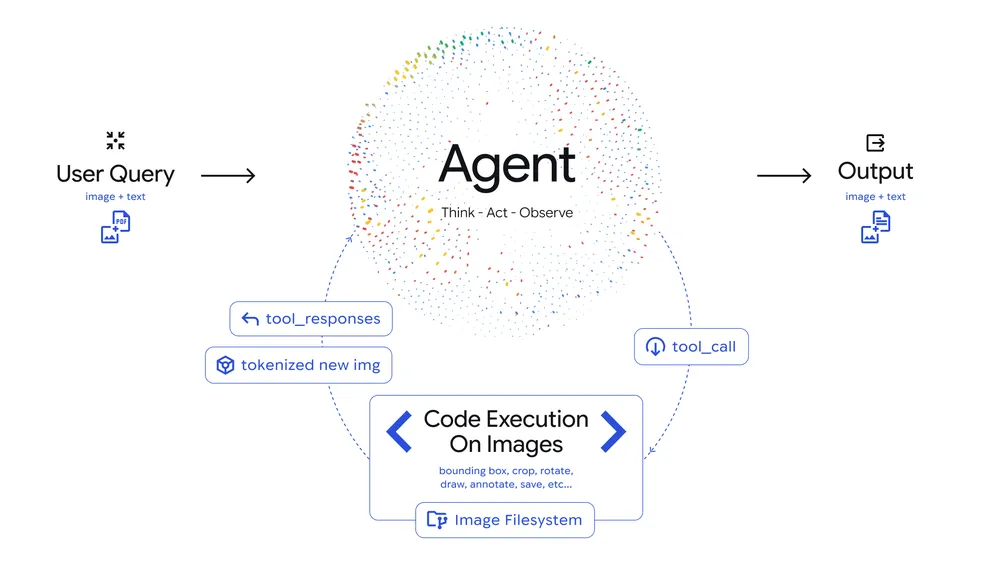
Google heeft een baanbrekende update aangekondigd voor zijn AI-model Gemini 3 Flash: Agentic Vision — een nieuwe visuele AI-capaciteit die het statische verwerken van beelden omvormt tot een dynamische, actieve analyse. In plaats van slechts één blik over een afbeelding te werpen en te raden, plant Gemini nu meerdere stappen van inspectie, bewerking en observatie om antwoorden te onderbouwen met visuele bewijsvoering.

|
Introducing Agentic Vision in Gemini 3 FlashAgentic Vision, a new capability introduced in Gemini 3 Flash, converts image understanding from a static act into an agentic process |
Wat is Agentic Vision?
Traditionele multimodale modellen analyseren visuele input één keer en geven een antwoord op basis van die ‘eerste indruk’ — wat foutgevoelig kan zijn bij detailrijke taken zoals het lezen van kleine tekst of technische labels. Agentic Vision verandert dat fundamenteel door AI een actief onderzoeksproces te laten volgen waarin beeldanalyse en code-uitvoering samenwerken.
Dit proces werkt volgens een “Think-Act-Observe”-loop:
- Think – Het model interpreteert de vraag en de afbeelding en ontwerpt een stappenplan.
- Act – Het genereert en voert Python-code uit om de afbeelding te manipuleren of te bestuderen — bijvoorbeeld door te croppen, roteren of annoteren.
- Observe – De gemodificeerde beelden worden teruggevoerd in het contextvenster voor verdere analyse en een gefundeerd antwoord.
Praktische use-cases: Agentic Vision in actie
Google belicht in zijn demo-omgeving diverse scenario’s waarin Agentic Vision zijn meerwaarde laat zien.
1. Slimmer zoomen en inspecteren
In complexe beeldsets, zoals bouwplannen of technische tekeningen, kan Gemini 3 Flash automatisch inzoomen op relevante secties. Bijvoorbeeld: een AI-platform dat bouwplannen controleert verhoogde zijn accuraatheid met ongeveer 5 % door iterative inspecties die Python-code gebruiken om eigen crops te genereren.
2. Annoteren met pixel-precisie
In een demonstratie vroeg men het model om vingers op een hand te tellen. In plaats van simpelweg te antwoorden, gebruikte Gemini 3 Flash Python-code om bounding boxes en labels op de afbeelding te tekenen — een visuele kladblok-methode die fouten minimaliseert.
3. Visuele wiskunde en diagrammen
Agentic Vision kan gegevens uit afbeeldingen halen, Python-code gebruiken om berekeningen uit te voeren en de resultaten te plotten. Een voorbeeld toont het genereren van een professioneel Matplotlib-diagram op basis van visuele input, waarmee willekeurige gokantwoorden worden vervangen door verifieerbare, code-gedreven uitkomsten.
Waarom dit een AI-doorbraak is
Door code-uitvoering te koppelen aan visuele redeneerprocessen breekt Google met de traditionele beperking van enkel-visuele AI-modellen. Dit opent de deur naar :
- Nauwkeurigere interpretatie van complexe beelden
- Lagere kans op hallucinerende antwoorden
- Betere ondersteuning voor ontwikkelaars die visueel-intensieve workflows automatiseren
Volgens Google levert deze aanpak consistent een 5–10% kwaliteitsverbetering op bij visuele benchmarks.
Wat staat er op de roadmap?
Google laat doorschemeren dat het pas het begin is. De plannen omvatten :
- Verder automatiseren van code-gedreven beeldmanipulaties zonder expliciete prompt-aanwijzingen.
- Integratie met extra tools zoals web- en omgekeerde beeldzoekfuncties.
- Uitbreiding van Agentic Vision naar andere modellen naast Flash.
Beschikbaarheid en toegang voor ontwikkelaars
Agentic Vision is nu toegankelijk via de Gemini API in Google AI Studio en Vertex AI, en wordt geleidelijk uitgerold in de Gemini-app (onder de “Thinking”-instelling). Ontwikkelaars kunnen experimenteren met de functie in de AI Studio Playground door Code Execution in te schakelen.
Slotwoord
Met Agentic Vision tilt Google de visuele AI-ervaring naar een nieuwe dimensie: van passieve beeldinterpretatie naar actieve, code-gestuurde analyse. Dit kan niet alleen beeldinzichten betrouwbaarder maken, maar ook toepassingen versnellen die sterk leunen op visuele informatie — van technische validatie tot interactieve beeld-AI-hulpmiddelen.









