
Bij MiniMax draait AI-ontwikkeling niet langer alleen om ruwe modelarchitecturen. Met hun nieuwste vlaggenschipmodel M2.1 hebben onderzoekers een nieuwe fase van post-training ingezet — een proces dat een model verfijnt, robuuster maakt en build-klaar brengt voor echte agent-toepassingen.
Van GitHub naar training: data-pijplijn als motor
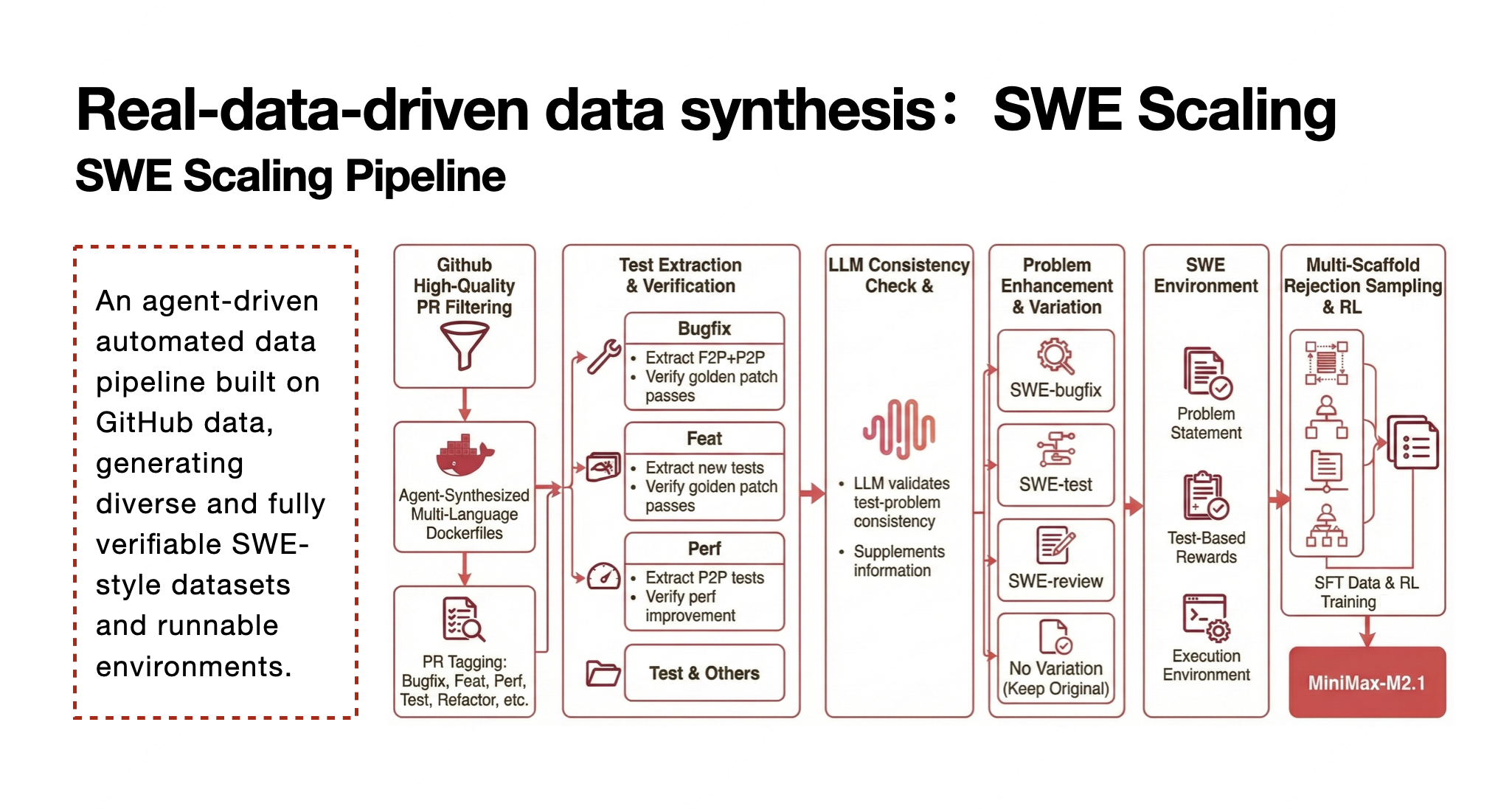
De post-trainingstrategie begint bij de bron: echte data uit GitHub. MiniMax werkt met duizenden Pull Requests (PR’s) en commits om representatieve code-taken te creëren. Elk PR-record wordt eerst gefilterd op kwaliteit en daarna in een bruikbare Docker-omgeving gebracht, een taak waar agenten zelf in worden getraind.
Het doel? Een enorme en diverse dataset genereren die niet alleen bugs uitdraagt, maar ook feature-uitbreidingen, performance-verbeteringen, test-constructies en meer — allemaal kritisch voor echte software engineering-scenario’s.
Slim omgaan met verschillende soorten code-taken
PR’s zijn niet gelijk; sommige bevatten bugs, andere introduceren nieuwe functies. MiniMax herkent deze verschillen en behandelt elk type taak met een specifieke aanpak. Voor bugfixes worden traditionele testcases gebruikt om te valideren of een patch echt werkt zonder nieuwe bugs te introduceren. Voor feature-uitbreidingen richt het team zich op de nieuwe tests die bij die functies horen, en voor performance-optimalisaties wordt gekeken naar stabiele prestatieverschillen vóór en na de wijziging.
Wanneer tests tekortschieten: het model helpt zichzelf
Niet alle GitHub-data zijn netjes gestructureerd; soms passen testcases niet goed bij de probleemomschrijving. MiniMax pakt dit aan door het model in te zetten om inconsistenties te detecteren en indien nodig de probleemomschrijving aan te vullen zodat deze oplosbaar wordt — een eerste stap richting zelfcorrigerende training.
Data-augmentatie en nieuwe taakvormen
MiniMax’s team beperkt zich niet tot één gebruik van data. Door bestaande taken te transformeren — zoals extra bugs injecteren, commits samenvoegen of taken omzetten naar testgeneratie-uitdagingen — kunnen ze een veel rijkere dataset creëren. Ook code-reviewtaken worden opgenomen, waarbij agenten statische analyse uitvoeren en fouten identificeren, wat de diversiteit van trainingsscenario’s vergroot.
De uiteindelijke SWE-dataset: een trainingsmotor voor agenten
Het eindproduct van deze workflow is een zogenoemde SWE-dataset: een dataset geschikt voor Supervised Fine-Tuning (SFT) en Reinforcement Learning (RL). Deze bevat:
- Heldere probleemomschrijvingen
- Verifieerbare beloningen op basis van tests
- Runnable omgevingen in Docker
Door verschillende context-scaffolds en taakvarianten te gebruiken, leert het model niet alleen code te genereren, maar ook flexibel en adaptief te denken — cruciaal voor agent-toepassingen.
Schaal en prestaties: van Python tot tien talen
Dankzij de uitgebreide data-pijplijn bedekt MiniMax M2.1 vandaag meer dan tien belangrijke programmeertalen en duizenden taken die testbaar zijn in echte omgevingen. In benchmarks zoals Multi-SWE en SWE-bench presteert M2.1 significant beter dan zijn voorganger, vooral in meertalige en dynamische settings — een belangrijke mijlpaal voor AI-agenten die echte wereldproblemen moeten oplossen.
Wat dit betekent voor de toekomst van agent-AI
MiniMax’s aanpak laat zien dat post-training veel meer is dan finetuning: het is een strategische investering in schaalbaarheid, robuustheid en praktische toepasbaarheid van modellen als volwaardige agenten. Door real-world data en verifieerbare tests als kern van training te gebruiken, zetten zij een nieuwe standaard voor wat AI-agenten kunnen leren én presteren.









