De AI die écht kijkt — en begrijpt
In een belangrijke vernieuwing voor multimodale AI introduceert Google een gloednieuwe visuele intelligentie-functie—Agentic Vision—in zijn krachtige model Gemini 3 Flash. In plaats van slechts een oppervlakkige blik te werpen op beelden en te gokken wat erin staat, kan de AI nu als een onderzoeker te werk gaan: hij denkt, onderneemt actie en observeert opnieuw, helemaal in een iteratieve onderzoekslogica.
Tot nu toe moesten AI-modellen vaak vertrouwen op een statische interpretatie van een afbeelding. Ontbrekende details — zoals kleine tekst of verafgelegen objecten — konden leiden tot onnauwkeurige antwoorden. Met Agentic Vision verandert dat: de AI krijgt een actieve rol in beeldverkenning.

|
Introducing Agentic Vision in Gemini 3 FlashAgentic Vision, a new capability introduced in Gemini 3 Flash, converts image understanding from a static act into an agentic process |
Actieve visuele intelligentie: Hoe werkt het?
Agentic Vision voegt een “Think–Act–Observe”-cyclus toe aan de visuele verwerking. In simpele woorden:
- Denkfase: het model bekijkt de vraag en de afbeelding en bedenkt een plan.
- Actiefase: de AI genereert en voert automatisch code uit om de afbeelding te manipuleren — denk aan inzoomen, bijsnijden of annoteren.
- Observeerfase: de aangepaste beelden worden teruggegeven aan het model, zodat het met een rijker context raamwerk antwoord kan geven.
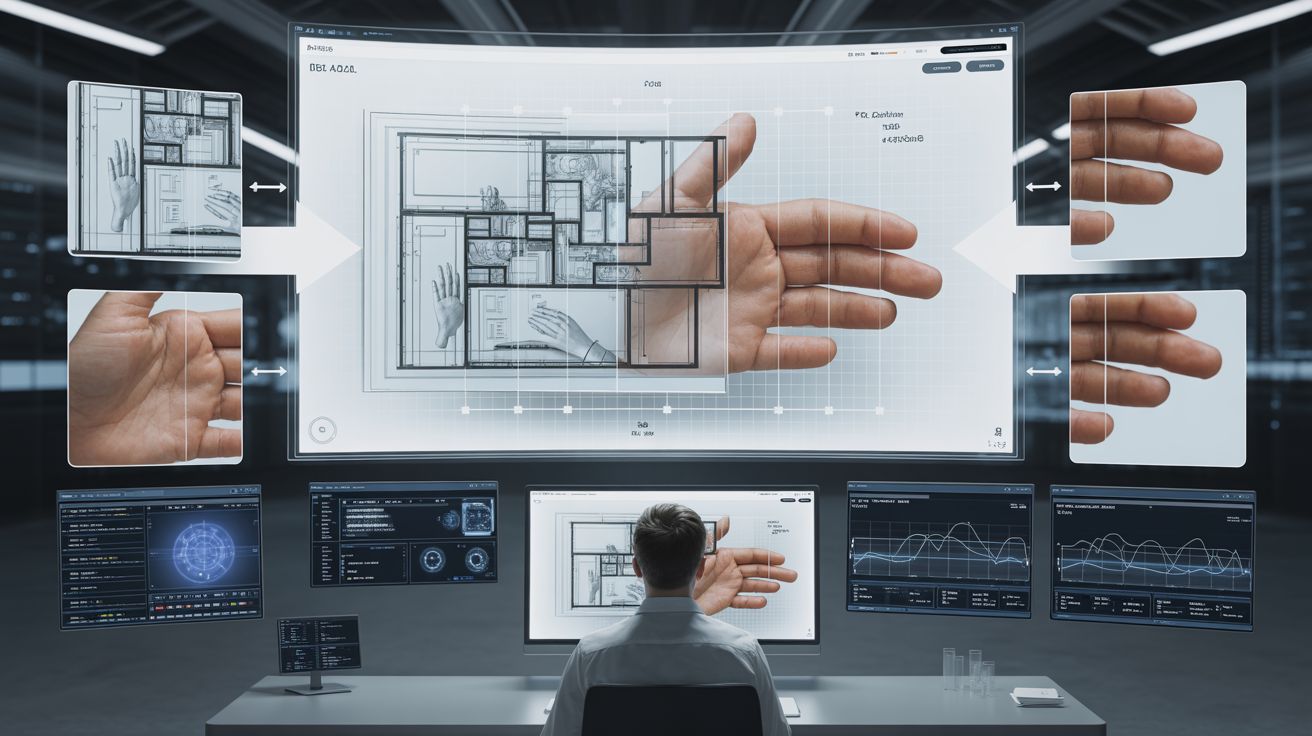
Door deze benadering kan de AI nadenken alsof een mens een foto met een vergrootglas bestudeert — en de details echt begrijpen, in plaats van ze slechts te beschrijven.

Praktische voorbeelden: Van bouwplannen tot visuele berekeningen
De nieuwe visuele intelligentie gaat verder dan alleen betere beschrijvingen:
- Precisie-inspecties: Een bouwplan-validatiesysteem gebruikte Agentic Vision om iteratief kleine details van architecturale tekeningen in te zoomen en nauwkeuriger te controleren op naleving van voorschriften.
- Annoteren in de praktijk: In demonstraties telt de AI bijvoorbeeld de vingers van een handbeeld niet meer zomaar — in plaats daarvan genereert hij automatisch kaders rond elk afzonderlijk object om fouten te vermijden.
- Visuele wiskunde en grafieken: In gevallen waar tabellen in afbeeldingen verborgen gegevens bevatten, kan de AI zelfstandig code genereren die de data exact analyseert en visualiseert — zoals professionele grafieken — in plaats van te gokken op basis van tekst alleen.
Deze aanpak verlaagt de kans op zogenaamde hallucinaties (foutieve interpretaties) drastisch en verhoogt de betrouwbaarheid van visuele analyses.

Wat betekent dit voor de toekomst?
Agentic Vision markeert een duidelijke verschuiving in de verwachtingen van beeld-AI. Door visuele context actief te onderzoeken en te manipuleren op basis van code-uitvoering, beweegt Gemini 3 Flash zich richting een meer autonome, betrouwbare en controleerbare vorm van visuele intelligentie.
Volgens Google levert de combinatie van visueel redeneren en code-uitvoering een consistente verbetering van 5 – 10% op diverse vision benchmarks — een aanzienlijke stap vooruit voor toepassingen waarbij nauwkeurigheid cruciaal is.
De functie is inmiddels beschikbaar via de Gemini API in Google AI Studio, Vertex AI en begint uitgerold te worden in de Gemini-app — wat ontwikkelaars en bedrijven nieuwe mogelijkheden biedt om visuele AI-workflows te bouwen en te verfijnen.









