
Generatieve AI heeft de sprong gemaakt van nieuwsgierige experimenten naar bedrijfskritische toepassingen. Maar hoe weet je eigenlijk of zo’n AI-systeem betrouwbaar, veilig en effectief is? Google Cloud presenteert een heldere, praktijkgerichte route om AI-evaluatie te professionaliseren — van simpele model-antwoorden tot geavanceerde agentgedreven workflows.
Van subjectieve vibes naar data-gedreven metrieken
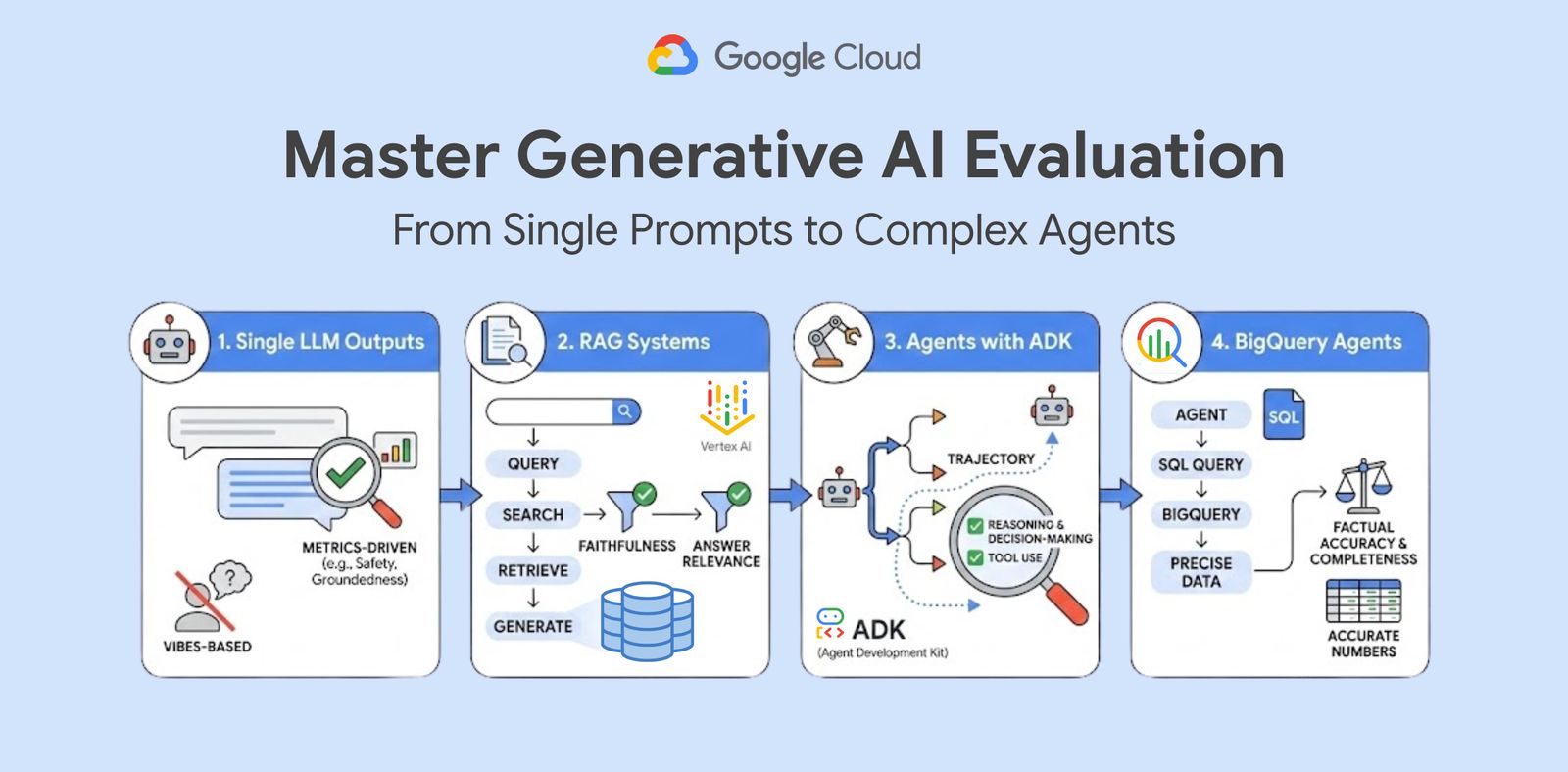
In veel ontwikkelteams blijft AI-evaluatie steken bij een simpele blik op de gegenereerde output: “Ziet er goed uit, toch?” Google Cloud pleit voor een rigoureuze aanpak waarin data en statistieken echt meten wat de AI doet. Denk aan veiligheid, relevantie en juistheid — niet alleen het eindresultaat, maar ook het pad ernaartoe.
|
Master Generative AI Evaluation: From Single Prompts to Complex Agents | Google Cloud BlogMaster the critical step of GenAI evaluation. Learn to move your LLM, RAG, and complex agent applications from prototype to production using a rigorous, metrics-driven approach with hands-on labs for Vertex AI Evaluation and the Agent Development Kit (ADK). |
Eerst leren hoe een enkele prompt presteert
Iedere AI-workflow begint met een enkele prompt. Google Cloud introduceert daarom een eerste stap waarmee ontwikkelaars leren om met geautomatiseerde tools de prestaties van losse modelreacties te evalueren. Zo leer je systematisch te definiëren welke kenmerken belangrijk zijn — zoals veiligheid en instructienaleving — en kun je LLM-reacties tegen datasets testen.
Evaluatie van RAG-systemen: niet alleen de antwoorden tellen
Retrieval Augmented Generation (RAG) combineert zoekresultaten met gegenereerde tekst — maar dit kan misgaan op twee plekken: bij het ophalen van documenten én bij het genereren van samenvattingen. Met Google’s evaluatielabs kun je beide componenten gescheiden beoordelen, en precies zien waar verbetering nodig is.
Agenten evalueren: Traject én resultaat onder de loep
AI-agenten zijn dynamisch: ze plannen stappen en gebruiken “tools” tijdens het proces. Daarom is het niet genoeg alleen naar het eindresultaat te kijken. Google Cloud laat zien hoe je agentscore kunt visualiseren aan de hand van het traject dat de agent aflegt, en hoe je concrete criteria opstelt voor elke stap van het denkproces.
BigQuery-agenten: Feiten boven veronderstellingen
Wanneer AI-agenten data uitlezen uit systemen zoals BigQuery, moet je controleren of de resultaten feitelijk juist zijn en volledig. Een fout SQL-query kan niet alleen “verkeerde output” geven — het kan hele bedrijfsbesluiten raken. Google’s evaluatietools helpen dit soort scenario’s zorgvuldig te toetsen.
Hands-on labs: Leren door te doen
Om teams hiervan te overtuigen, heeft Google vier praktische labs ontwikkeld waarin je stap voor stap leert omgaan met evaluatie-tools — van basispromptchecks tot geavanceerde agentanalyse met het Agent Development Kit (ADK).
De weg naar productie-klare AI
Evaluatie hoort niet aan het einde van het ontwikkeltraject — het is de brug naar AI die je met vertrouwen in productie kunt inzetten. Door systematisch zicht te krijgen op risico’s, afwijkingen en prestaties maak je generatieve AI niet alleen bruikbaar, maar ook betrouwbaar en schaalbaar.
Waarom dit relevant is voor AI-bouwers
In een tijd waarin generatieve AI steeds verder wordt ingezet — van data-analyse tot geautomatiseerde besluitvorming — is de kwaliteit van evaluatie cruciaal. Teams die leren om AI met meetbare parameters te beoordelen, bouwen betere, veiligere en bedrijfskritische applicaties.









